



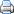
Jeroen Stoop, Sjoerd Staffhorst, Remco Bekker en Tjerk Hobma gaan in het boek Business- & Informatieplanning - Een raamwerk voor organisatieverbetering in op het nut en de noodzaak van een bedrijfsobjectenmodel en een informatiedomeinenmodel. Hieronder een beknopte weergave van hoe beide modellen kunnen helpen bij het optimaliseren van de ondersteuning die de informatievoorziening biedt aan processen.
Bedrijfsobjectenmodel
Informatievoorziening levert de informatie die nodig is voor de uitvoering en besturing van processen. De uitvoering en besturing processen heeft informatie nodig. In deze informatiebehoefte wordt voorzien door informatiesystemen.
Voor elk proces kunnen de informatiebehoeften in beeld worden gebracht. Voor het in kaart brengen van de informatiebehoeften is het nodig te weten wat de 'onderwerpen van gesprek' zijn. Waarover praten de deelnemers aan het proces en wat willen ze hier dan van weten.
![]()
[De] 'onderwerpen van gesprek' noemen we bedrijfsobjecten. Het zijn de 'dingen' waarvan we de eigenschappen in de vorm van gegevens willen vastleggen, gebruiken en beheren. Deze 'dingen' kunnen betrekking hebben op fysieke objecten die we kunnen aanwijzen, zoals gebouwen, mensen of producten, maar ook op abstracte objecten, zoals verzekeringspolissen, organisaties of vorderingen. Objecten kunnen ook betrekking hebben op gebeurtenissen, bijvoorbeeld, een levering of een uitvaart.
Voor het verkrijgen van een gestructureerd overzicht van de objecten waarvan we eigenschappen in de vorm van gegevens willen vastleggen, kunnen we gebruik maken van een bedrijfsobjectenmodel. In het bedrijfsobjectenmodel draait het om het definiëren van de objecten, het begrijpen hoe de bedrijfsobjecten samenhangen en het onderkennen van de belangrijkste eigenschappen van die objecten.
(...)
Het is ook mogelijk om een model uit de datamodellering te gebruiken, zoals een entiteitsrelatiediagram (ERD). Bij het kiezen van de manier waarop de gegevens worden beschreven is het van belang om het doel van het model in de gaten te houden. Meestal is veel detaillering niet nodig en gaat het om de belangrijkste objecten met hun belangrijkste eigenschappen. Een bedrijfsobjectenmodel leent zich hiervoor het best. Het hoeft namelijk geen ontwerp van een informatiesysteem te zijn.
Informatiedomeinenmodel
Novius stelt dat voor het maken van toekomstvaste keuzes voor de inrichting van de informatievoorziening het nodig is te beschikken over een ideaaltypische afbakening van de informatiedomeinen.
![]()
"Stel dat we van een organisatie de end-to-end-processen (op hoofdlijnen) in kaart hebben gebracht. En stel vervolgens dat we ook van deze processen de informatiebehoeften (op hoofdlijnen) in kaart hebben. Dan kan de vraag worden gesteld welke informatiesystemen idealiter geïmplementeerd moeten worden om in de informatiebehoeften van de processen te voorzien. Deze vraag draait om een optimale afbakening van de informatiesystemen van een organisatie. Een optimale afbakening van de informatiesystemen zorgt voor flexibiliteit in processen en informatiesystemen enerzijds en voor samenhang en uniformiteit tussen processen en informatiesystemen anderzijds.
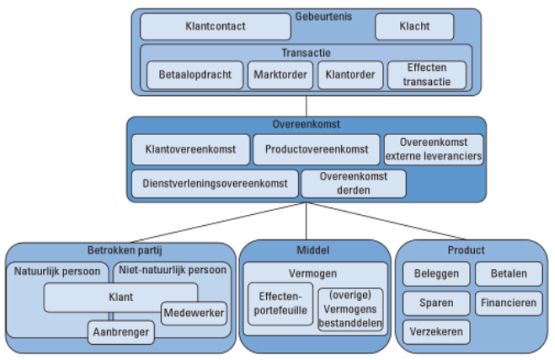
... Processen krijgen hun informatie aan de hand van gegevens die eigenschappen van bedrijfsobjecten representeren. Maar in processen komen ook nieuwe gegevens beschikbaar over bedrijfsobjecten die vastgelegd moeten worden. Informatiesystemen beheren samenhangende clusters van gegevens voor de processen om tijd en plaats te overbruggen (tijd: gegevens die we vandaag vastleggen hebben we ooit in de toekomst weer nodig; plaats: gegevens kunnen we op verschillende locaties nodig hebben). Het is hierbij wenselijk om clusters van processen te bepalen met een sterke interne samenhang voor wat betreft de informatiebehoeften en met zwakke externe informatie-uitwisselingen (loose coupling en tight cohesion). Dergelijke clusters worden ook wel informatiedomeinen of logische informatiesystemen genoemd.
We onderscheiden twee technieken die kunnen helpen bij het onderkennen van informatiedomeinen:
(1) Gebruik van het bedrijfsfunctiemodel als startpunt voor het informatiemodel.
Bedrijfsfuncties zijn ook logisch afgebakende clusters van activiteiten, mensen en middelen. In gegevensverwerkende organisaties heeft die afbakening dan ook logischerwijs veel te maken met de gegevensverwerking die plaats dient te vinden in een bedrijfsfunctie. Vandaar dat dit een goed startpunt is om per bedrijfsfunctie een informatiedomein te onderkennen.
(2) Opstellen van een CU- of CRUD-matrix
We kunnen processen ook in een matrix afzetten tegen de gegevensverwerking van die processen. Dit wordt ook wel een CU- of CRUD-matrix genoemd. De letters C en U staan voor Create en Use en de letters CRUD voor Create, Read, Update en Delete. In deze matrices staan op de verticale as de werkprocessen of processtappen, en op de horizontale as de bedrijfsobjecten. In de cellen van deze matrix wordt dan vastgelegd welke acties (C en U dan wel C, R, U of D) het betreffende werkproces of de betreffende processtap uitvoert op het betreffende bedrijfsobject of de betreffende entiteit. Door te schuiven met de kolommen en rijen van de matrix kunnen we op zoek gaan naar clusters van grote samenhang tussen een groep werkprocessen of processtappen enerzijds en een groep bedrijfsobjecten of entiteiten anderzijds. Een dergelijk cluster representeert een informatiedomein.
In de praktijk blijkt het dat met de tweede techniek moeilijker is om tot goede resultaten te komen dan met de eerste. Om die reden wordt de tweede techniek dan ook aanvullend ingezet, als dat nodig is, om discussies over de afbakening te slechten.
(...)
Het informatiedomeinenmodel is een belangrijk model voor de afstemming van de bedrijfsvoering en de informatievoorziening. Het is de stap naar de functionaliteiten en informatie die nodig zijn voor de uitvoering van de processen. Het informatiedomeinenmodel biedt een overzicht van de benodigde informatievoorziening los van de fysiek invulling met applicaties. In de praktijk is dit een zeer handige tussenstap. Vaak is men geneigd om te blijven denken in termen van het huidige applicatielandschap. Met het informatiedomeinenmodel komt men hier meer los van, wordt het gemakkelijker om discussies over applicatiegrenzen te voeren en wordt het denken in scenario's vergemakkelijkt.
De kapstokfunctie van het informatiedomeinenmodel (dat overigens vaak op één A4-tje is weer te geven) is erg nuttig. De huidige en in ontwikkeling zijnde applicaties, de gegevensstromen, de verantwoordelijkheden voor informatiedomeinen, de huidige knelpunten: allemaal voorbeelden van zaken die op het informatiedomeinenmodel 'geplot' kunnen worden.
Het applicatielandschap en de gewenste functionaliteiten van de informatievoorziening
[Applicaties geven] een fysieke invulling aan (een deel van) één of meerdere informatiedomeinen. Een applicatie is een verzameling van geautomatiseerde en verwante functionaliteiten, samen met de gegevens die door die functionaliteiten worden beheerd, met een eigen planning van nieuwe versies, release en aanpassingen.
Een applicatie kan door een organisatie zelf zijn ontwikkeld, maar vaak worden applicaties gekocht. Het geheel van applicaties wordt ook wel het applicatielandschap genoemd.
(...)
Als we het applicatielandschap vanaf de grond zouden opbouwen en zouden willen optimaliseren voor samenhang en flexibiliteit, dan zou het applicatielandschap bestaan uit applicatie(module)s, die elk één informatiedomein afdekken. Het applicatielandschap ziet er dan hetzelfde uit als het informatiedomeinenmodel.














